How Data Centers are enabling Artificial Intelligence (AI)

The rapid growth of data generation fueled by artificial intelligence (AI) has transformed how data is stored, processed, managed, and transferred, while increasing the demand for computing power across cloud and edge data centers. To meet the demand generated by AI, data centers are evolving and adapting their design, power infrastructure, and cooling equipment in various unique ways.
Data centers provide vast computing resources and storage, enabling artificial intelligence (AI) to process massive datasets for training and inference. By hosting specialized hardware such as GPUs and TPUs, data centers accelerate complex calculations, supporting AI applications and workloads.
As Dgtl Infra delves deeper into the evolving relationship between artificial intelligence and data centers, we offer insights on power consumption, cooling requirements, and the pivotal role of data centers in supporting AI. We also present an intriguing case study on Meta Platforms’ AI data centers and explore the various types of data centers utilized for AI applications.
Artificial Intelligence drives the need for Data Centers
Artificial intelligence (AI) is swiftly becoming the driving force behind modern technologies across various industries, with applications in optimization, preventive maintenance, virtual assistants, fraud detection, and anomaly detection. The success of these AI applications hinges on the availability of vast amounts of data, consequently leading to a growing demand for data centers to store and process this information.
As more organizations incorporate AI into their operations, there is a corresponding rise in data generation. For instance, generative AI, including large language models (LLMs) like ChatGPT, employs extensive training data to generate contextually relevant and coherent content based on user input.
Similarly, autonomous vehicles produce large amounts of data through their LiDAR sensors, high-resolution cameras, and radar systems. This data is essential for training the machine learning (ML) models that power AI systems, necessitating storage, processing, and real-time analysis in data centers.
Role of Data Centers in supporting Artficial Intelligence
Data centers provide secure, scalable, and reliable infrastructure for storing, processing, and analyzing the large amounts of data generated by AI applications. At the same time, AI workloads are often both data and compute-intensive.
Data centers support AI through high-performance computing (HPC), hosting specialized hardware, data storage, and networking. At the same time, these specialized buildings are equipped with power and cooling infrastructure (discussed in the following sections) to ensure that all of their internal hardware functions properly.
1) High-Performance Computing (HPC)
Artificial intelligence (AI) applications require enormous amounts of computing power, driven by both the training and inference workloads associated with their AI models.
Data centers support AI applications and workloads using high-performance computing (HPC) clusters. These clusters consist of multiple servers connected through high-speed networks, allowing for parallel processing and faster training times.
In a data center, a high-performance computing (HPC) system is often designed to fit into a standard 19-inch wide four-post rack. This is a common form factor for data center equipment, designed to accommodate rack-mounted servers (e.g., 1U servers), blade servers, networking equipment, and storage arrays. These systems are modular and scalable, making it easy to install and upgrade capacity as the needs of AI applications and workloads change.
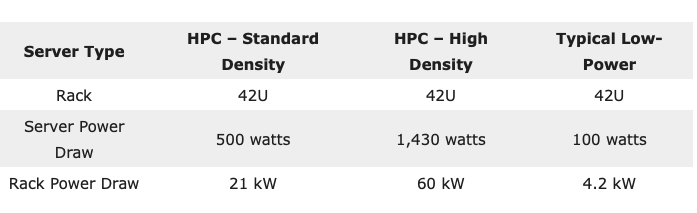
In this HPC system, the power density of a single rack can range from 20 kilowatts (kW) to over 60 kW. For example, a 42U rack filled with 1U servers consuming a “standard” 500 watts each, would draw a total of 21 kW of power. Scaling up this example to “high” density, a 42U rack filled with 1U servers consuming 1,430 watts each, would draw a total of 60 kW of power. In contrast, a typical low-power server, such as those designed for web hosting, may consume only 100 watts of power, implying a total power draw of 4.2 kW for a 42U rack filled with 1U servers.
2) Specialized Hardware used in HPC Systems
HPC systems utilize a combination of high-powered processors (CPUs), high-speed memory, and specialized hardware such as GPUs to efficiently process large amounts of data and support AI workloads. These high-end processors are capable of quickly and efficiently performing complex computations and data analysis. To this end, the use of such processors ensures that the HPC system can handle demanding workloads, including data mining, scientific simulations, advanced analytics, and machine learning (ML) tasks, with fast processing speeds and minimal latency.
Deep learning (DL) models and real-time AI require specialized computing accelerators for deep learning algorithms. Initially, this type of computing relied on widely deployed graphics processing units (GPUs). However, several cloud service providers have since developed their own custom chips, such as Google’s Tensor Processing Unit (TPU), which is an application-specific integrated circuit (ASIC), and Microsoft’s Project Catapult which uses field-programmable gate arrays (FPGAs), to meet the increasing demand of these AI workloads.
Specialized hardware, such as GPUs, ASICs, and FPGAs, can accelerate machine learning algorithms, making them an essential component of modern HPC systems. These specialized processors are designed to perform matrix computations, making them particularly effective for machine learning tasks that involve processing large amounts of data in parallel. By leveraging these specialized processors, HPC systems can significantly accelerate the processing of AI workloads.
3) Data Storage
Artificial intelligence (AI) models require vast amounts of data for training and inference, and data centers provide the necessary storage capacity to house these datasets. Additionally, AI applications perform a large number of input/output (I/O) operations, such as reading or writing data to storage devices and exchanging information between devices over a communications network.
High-speed storage access is essential for AI workloads like machine learning, deep learning, and data processing, which demand rapid data access and transfer rates from their storage systems. This fast access enables AI models to efficiently read, write, and process data – in real-time or near real-time – resulting in improved performance and reduced latency in tasks like training, inference, and data analysis.
Data centers typically use high-capacity storage devices such as hard disk drives (HDDs), solid-state drives (SSDs), and network-attached storage (NAS) to house and manage large AI datasets. While the cloud service providers (CSPs), including Amazon Web Services (AWS), Microsoft Azure, and Google Cloud, offer low-latency and high-throughput storage solutions as consumable services. For example, Amazon FSx for Lustre is a high-performance file system designed for compute-intensive workloads, including machine learning, high-performance computing (HPC), and big data processing.
4) Networking
AI workloads involve large matrix computations, which are distributed over hundreds and thousands of processors, such as CPUs, GPUs, and TPUs. These intense computations occur over a certain duration of time and demand a high-capacity, scalable, and error-free network to effectively support these workloads. Moreover, the growing prevalence of use cases like AI clusters continues to stretch the limits of networking in terms of bandwidth and capacity requirements.
High-performance networking for AI workloads involve the following key features:
1. Throughput: when running large-scale AI applications, network bandwidth capabilities have significant implications for a data center’s performance, ultimately affecting the efficiency and speed of processing. Generally, GPU clusters require about 3x more bandwidth than traditional compute networks
2. Disaggregated AI Applications: with the advent of disaggregated AI applications, high-performance networking becomes even more critical. In this setup, various components of AI applications are distributed across different hardware and software resources, which reside on different servers and storage systems within a data center. Seamless communication between these components is required, which can only be achieved with a robust networking infrastructure, such as a 400 gigabits per second (Gbps) capacity network like the NVIDIA Mellanox 400G InfiniBand
3. Efficiency: the efficiency of an AI infrastructure is directly related to the performance of its networking. A slow network can create a bottleneck in the overall infrastructure, reducing the efficiency of the deployed AI applications. Therefore, a lossless AI fabric, connecting distributed infrastructure and integrating features such as congestion control and bandwidth management, is crucial to ensure the seamless functioning of AI workloads
Power Consumption of AI Data Centers
Artificial intelligence (AI) applications are driving up power usage and power density in data centers, as they require more power-intensive computations from servers and storage systems than traditional workloads. This increased power demand can put a strain on existing data center infrastructure.
To address the growing energy consumption issue, new data center architectures are focusing their engineering efforts on power density and scalable design:
Power Density
On average, the power density in a traditional data center ranges from 4 kW per rack to 6 kW per rack. However, this range has been steadily increasing as a greater number of AI and ML workloads have begun to be deployed more frequently in data centers. Furthermore, the average power density of data centers is expected to continue to increase, driven by rapid growth in data traffic and computing power.
In larger hyperscale data centers, which are facilities with power capacities of 5 to 100 megawatts (MW), power densities are typically higher than in traditional data centers. These facilities primarily support cloud service providers (CSPs), such as Amazon Web Services (AWS), and large internet companies, like Meta Platforms, and operate at power densification levels of 10 kW per rack to 14 kW per rack. Larger organizations typically have more complex IT requirements, benefit from economies of scale, and have substantial budgets to implement sophisticated AI infrastructure and power-intensive, high-density computing.
Additionally, power for newer extreme density AI workloads is pushing densification ranges to between 20 kW per rack and 40 kW per rack, and in some specialized computing operations, hotspot densities of 60 kW per rack or more. For example, these densities are being implemented by financial services firms, visual effects (VFX) companies, and film studios, as well as certain hyperscalers, such as Meta Platforms (see forthcoming section).
Overall, when rack densities reach these extreme levels, the equipment generates a significant amount of heat. As a result, high power densification levels necessitate unique data center engineering approaches. Often, the facility operator creates a dedicated area or specialized section within a larger data center specifically designed to support these resource-intensive AI workloads.
Scalable Design
Data center designs are being strategically engineered to accommodate scalable expansion, allowing for cost-effective capital expenditure over the long-term. Considering the typical lifecycle of a data center spans between 10 to 15 years, while IT equipment (e.g., servers and network gear) has a significantly shorter lifespan of 3 to 5 years, it is crucial to develop a future-proof design that addresses the evolving power density demands of AI applications and workloads.
To achieve this, newer data center designs support hybrid deployment of IT devices, incorporating a variety of power densities to cater to a diverse range of customers. Additionally, by securing extra unused power capacity from their electric utility company, data center operators can ensure they have a reliable energy supply for future expansion. This approach ensures that as the requirements for AI applications become more complex and intense, data center infrastructure can seamlessly adapt without the need for frequent and costly upgrades.
Cooling Requirements of AI Data Centers
Artificial intelligence (AI) applications and workloads require IT equipment to run at high power densities, which generate a significant amount of heat, leading to an increase in server cooling requirements. Consequently, data centers face increased cooling challenges and often need to be redesigned or re-engineered to maintain appropriate temperature levels within the facility. Inefficient cooling can result in reduced equipment life, poor computing performance, and greater demand on cooling systems.
Two commonly used cooling methods to address these heightened cooling challenges are liquid cooling and immersion cooling. Particularly, power densification levels above 30 kW per rack are where hotspots start to become present, and unique strategies, such as liquid cooling, are needed. At power densities of 60 kW per rack to 80 kW per rack, direct-to-chip liquid cooling becomes more common.
Liquid Cooling
Liquid cooling is a method that involves circulating a coolant, such as water or specialized fluids like 3M Novec or Fluorinert, through cold plates in direct contact with electronic components, such as CPUs or GPUs. The heat is absorbed by the liquid coolant, transported through a heat exchanger or radiator where the heat is dissipated into the air. The cooled liquid is then recirculated.
Liquid cooling is particularly effective in managing high-density AI workloads, as it can dissipate heat more efficiently than traditional air-cooling systems. Notably, liquids are thousands of times more efficient per unit volume than air at removing heat. This makes it logical to cool internal hardware electronics with circulating liquid that can remove large volumes of heat in small spaces and transfer the heat to another medium, such as air outside the hardware.
Overall, liquid-cooled systems are desirable for high power densities. However, liquid cooling typically cools only the CPU or GPU, leaving some heat in the room, which may present a significant cooling load. Therefore, liquid-cooled systems require additional air conditioning to cool other components.
Immersion Cooling
Immersion cooling is a method where electronic components are submerged in a non-conductive liquid coolant, like 3M Novec or Fluorinert. The coolant absorbs the heat generated by the components and is circulated to a heat exchanger for cooling before recirculation. Immersion cooling not only cools the CPU but also other components on the printed circuit board (PCB) or motherboard.
Immersion cooling is gaining traction due to its ability to enable higher power density and lower power usage effectiveness (PUE) for data centers that operate high-performance computing (HPC) environments. Unlike liquid cooling, which cools only the CPU and/or GPU, immersion cooling lowers the temperature for the entire board on which these components are mounted.
Case Study – Meta Platforms AI Data Centers
Meta Platforms, previously known as Facebook, is a technology company offering social media and social networking services. To support this business, Meta owns and operates 21 data center campuses worldwide, spanning over 50 million square feet, in addition to leasing several more data centers from third-party operators. In 2023, the company is focusing a significant portion of its $30+ billion in capital expenditures on expanding its artificial intelligence (AI) capacity, primarily through investments in GPUs, servers, and data centers.
Meta is “building new data centers specifically equipped to support next-generation AI hardware”. The company’s AI investments and capacity benefit various products and services, such as Ads, Feed, Reels, and the Metaverse. To-date, Meta has seen “encouraging results” for these services by using “GPU clusters at-scale”, which are groups of GPUs working together to handle complex AI workloads more efficiently and effectively.
Meta’s Grand Teton GPU-based hardware platform boasts several performance enhancements over its predecessor, Zion. These include 4x the host-to-GPU bandwidth, 2x the compute and data network bandwidth, and 2x the power envelope. Grand Teton has been designed with increased compute capacity to more effectively support memory-bandwidth-bound workloads, such as Meta’s deep learning recommendation model (DLRM).
Overall, Meta aims to standardize its design across all data centers to accommodate high power density AI workloads, which can range from 25 kW per rack to 40 kW per rack. In turn, Meta is now partnering with data center operators capable of building cost-effective, high power density AI infrastructure.
Liquid Cooling by Meta Platforms
Meta has been utilizing liquid cooling technology to maintain optimal operating temperatures for their servers, which support high power density AI workloads. In particular, Meta employs air-assisted liquid cooling (AALC) through a closed-loop system and a rear-door heat exchanger, enabling server cooling without the need for a raised floor or external pipes. This advancement forms part of Meta’s transition to a more robust design for its data centers, necessitating an increased use of liquid cooling technologies.
Types of Data Centers used for AI
Artificial intelligence (AI) applications and workloads make use of high power density racks, which are deployable across various types of facilities, from large hyperscale/cloud data centers to small edge data centers.
Hyperscale/Cloud Data Centers: cloud service providers such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud offer AI-specific services that can be used to build and deploy AI models. Given the large size of these facilities, they are particularly well-suited for AI applications and workloads involving machine learning (ML) and deep learning (DL) training, big data analytics, natural language processing (NLP), and computer vision
_Edge Data Centers: _these are smaller, decentralized facilities that provide compute and storage in a location closer to where data is being generated and used. Edge data centers are designed for low-latency AI applications that require fast response times, such as real-time video analytics, augmented reality (AR) and virtual reality (VR), autonomous vehicles, and drones
Importantly, not all data centers can be optimized for a single use case due to the diverse requirements of different AI applications and systems. For instance, a deep learning and AI system requires a high CPU or GPU processor core count to reduce training time, whereas an inference engine used in AI can perform its job with a low processor core count.
Mary Zhang
Mary Zhang covers Data Centers for Dgtl Infra, including Equinix (NASDAQ: EQIX), Digital Realty (NYSE: DLR), CyrusOne, CoreSite Realty, QTS Realty, Switch Inc, Iron Mountain (NYSE: IRM), Cyxtera (NASDAQ: CYXT), and many more. Within Data Centers, Mary focuses on the sub-sectors of hyperscale, enterprise / colocation, cloud service providers, and edge computing. Mary has over 5 years of experience in research and writing for Data Centers.


